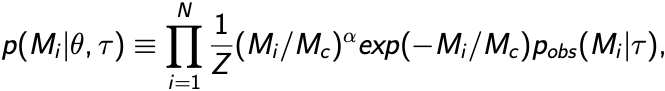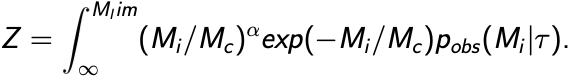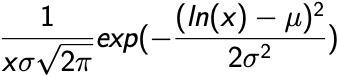Abstract:
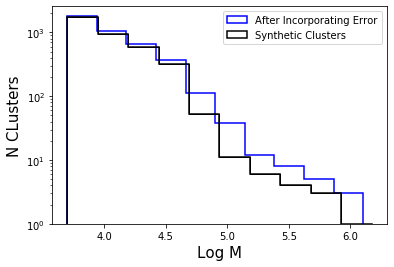
We measure the cluster mass function for 770 young star clusters in M31 whose ages and masses were derived through integrated light spectral energy distribution (SED) fitting. Although fits to integrated light observations lead to larger uncertainties than from other methods, a majority of extragalactic star cluster samples rely on integrated light fitting. We compare the integrated light SED mass function fitting results to the mass function results of these exact same clusters whose ages and masses were derived through color magnitude diagram (CMD) fitting previously published. Our mass function fitting, carried out using a probabilistic Markov chain Monte Carlo (MCMC) technique, confirms the existence of a high-mass truncation that is well described using a Schechter function. We find a power-law index of α = -1.91 ∓ 0.08 and a truncation mass of (logMc/M☉) = 4.35+0.13-0.10. This truncation mass is 0.4 dex higher than the previously published CMD value, suggesting that errors on the mass estimates of individual clusters can bias the upper mass truncation parameter of the cluster mass function to significantly higher values. We then run several experiments using M51, M83 and NGC628 incorporating individual cluster mass errors into a simulation mass function fit. We find that the high errors of the integrated light method of deriving ages and masses systematically biases the truncation mass towards higher masses.