Modeling Star Clusters Using CMC Program
Mohammed Harris Khan with Professor Fred Rasio and Sourav Chatterjee
Project under CIERA REU Program
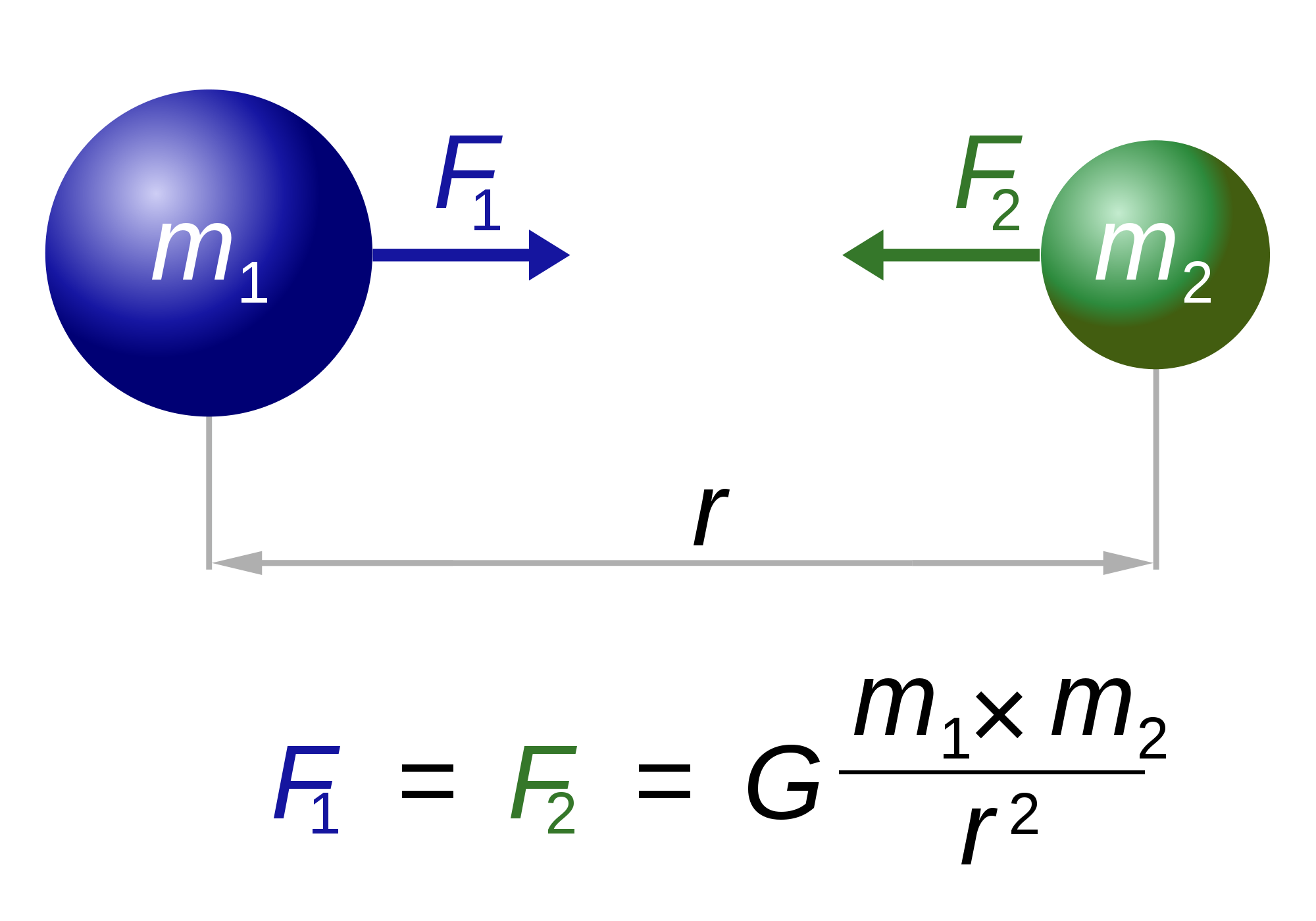
Star Cluster
There are two main types of star clusters: open and globular clusters.
The latter may have upwards of hundreds of thousands of stars. In order to simulate the motion of N stars precisely, this would require considering around the order of N2 forces.
Realistic Simulation Results
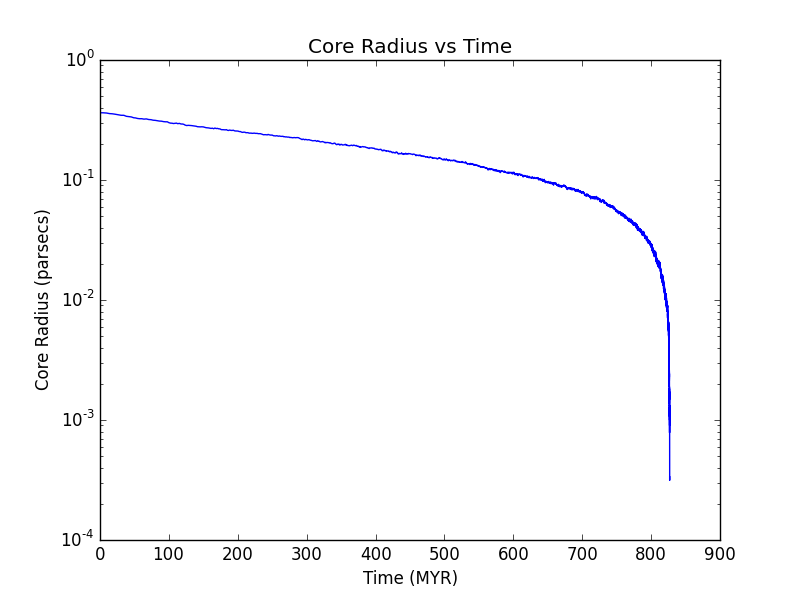
Before using the results of these simulations, we should verify that the approximation does well in predicting how long it takes for a given star cluster model to experience core collapse. Running the simulation on a plummer sphere , which treats stars as point masses, allows us to see that the results are as we expect them to be from a known textbook calculation.
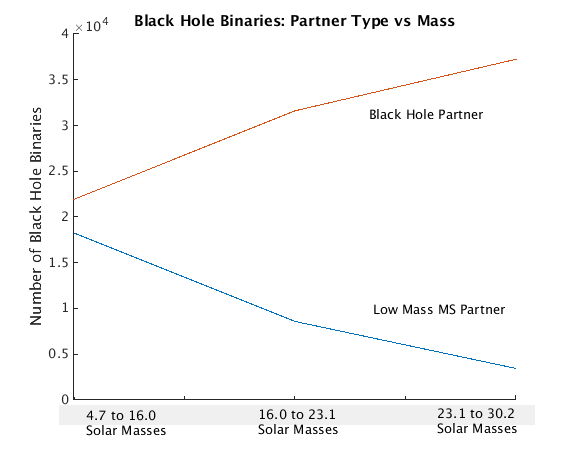
Black Hole Binary Partners
Another thing to consider is the types of stars which end up being more likely to enter into a binary star system with a black hole. How does the mass of the blackhole influence the type of stars that are likely to form a binary with it?
Use Monte Carlo to reduce time
It's not particularly useful to know the exact motion of the stars over time. As such, for a large number of stars, the probabilistic method of Monte Carlo can approximate this motion well. It is significantly faster, reducing the complexity of the algorithm from N2 to N log N. As such, it is the preferred algorithm to use.
 Example of Monte Carlo: Approximating Pi
Example of Monte Carlo: Approximating Pi
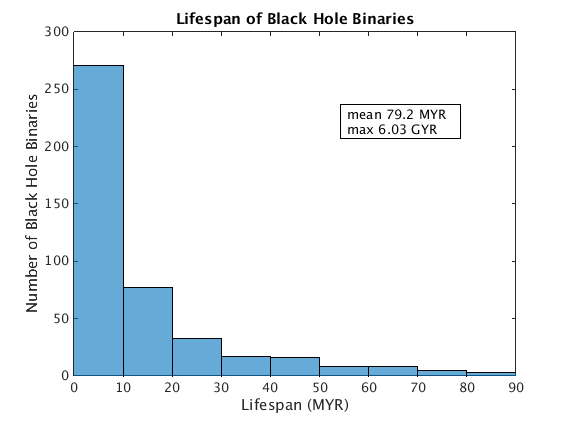
Lifespan of Black Hole Binaries
Running a simulation of a cluster of 80000 stars for 12 GYR gives a large amount of realistic data which can be analyzed to understand some interesting occurences in these types of clusters.
One interesting thing to consider is the lifespan of binary star systems in which at one of the stars is a black hole. Considering time from formation of the binary to disruption or ejection, we see interesting results in the range of lifespans.
Pause & Play
The original goal of this project, as well as my current focus and future goal is to create a checkpoint mechanism by which a simulation such as the one discussed may be resumed, given that it was already run up to a certain point.
Such a feature would save a lot of time, which is of the essence since running this simulation for large clusters still takes considerably long.


